Set Up
Learn how to set up Sentry LLM Monitoring
Sentry LLM Monitoring is easiest to use with the Python SDK and an official integration like OpenAI.
To start sending LLM data to Sentry, make sure you've created a Sentry project for your AI-enabled repository and follow one of the guides below:
Don't see your platform?
We'll be adding AI integrations continuously. You can also instrument AI manually with the Sentry Python SDK.
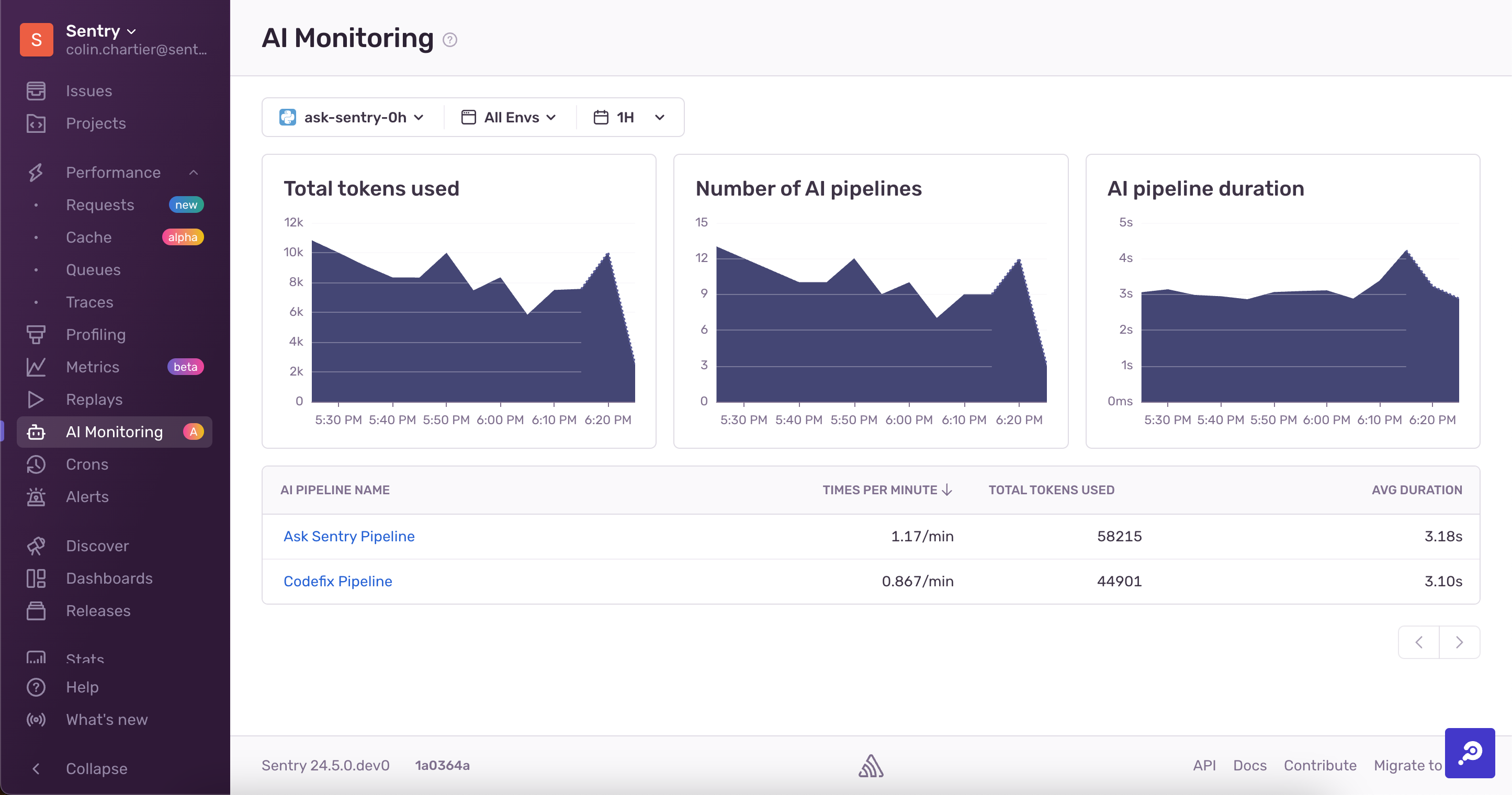
The Sentry LLM Monitoring feature relies on the fact that you have an orchestrator (like LangChain) creating pipelines of one or more LLMs (such as gpt-4). In the LLM Monitoring dashboard, we show you a table of the AI pipelines and pull the token usage from your LLMs.
If you're using a provider like OpenAI without an orchestrator like LangChain, you'll need to manually create pipelines with the @ai_track annotation. If you're using a non-supported LLM provider and want to record token usage, use the record_token_usage() helper function. Both manual helpers are documented below.
The Python SDK includes an @ai_track decorator which will mark functions as AI-related and cause them to show up in the LLM Monitoring dashboard.
import time
from sentry_sdk.ai_monitoring import ai_track, record_token_usage
import sentry_sdk
import requests
@ai_track(description="AI tool")
def some_workload_function(**kwargs):
"""
This function is an example of calling arbitrary code with @ai_track so that it shows up in the Sentry trace
"""
time.sleep(5)
@ai_track(description="LLM")
def some_llm_call():
"""
This function is an example of calling an LLM provider that isn't officially supported by Sentry.
"""
with sentry_sdk.start_span(op="ai.chat_completions.create.examplecom", description="Example.com LLM") as span:
result = requests.get('https://example.com/api/llm-chat?question=say+hello').json()
# this annotates the tokens used by the LLM so that they show up in the graphs in the dashboard
record_token_usage(span, total_tokens=result["usage"]["total_tokens"])
return result["text"]
@ai_track(description="My AI pipeline")
def some_pipeline():
"""
The topmost level function with @ai_track gets the operation "ai.pipeline", which makes it show up
in the table of AI pipelines in the Sentry LLM Monitoring dashboard.
"""
client = OpenAI()
# Data can be passed to the @ai_track annotation to include metadata
some_workload_function(sentry_tags={"username": "my_user"}, sentry_data={"data": "some longer data that provides context"})
some_llm_call()
response = (
client.chat.completions.create(
model="some-model", messages=[{"role": "system", "content": "say hello"}]
)
.choices[0]
.message.content
)
print(response)
with sentry_sdk.start_transaction(op="ai-inference", name="The result of the AI inference"):
some_pipeline()
Our documentation is open source and available on GitHub. Your contributions are welcome, whether fixing a typo (drat!) or suggesting an update ("yeah, this would be better").